
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Java
- Python
- CNN
- flatten
- 머신러닝(딥러닝)
- Database
- LeNet
- 생활코딩 데이터베이스
- pandas
- 생활코딩 머신러닝야학
- 카카오클라우드스쿨2기
- 연산자
- MySQL
- 데이터베이스
- 개발자
- 딥러닝
- 파이썬
- 판다스
- 이것이 자바다
- 야학
- 머신러닝
- 생활코딩
- JavaScript
- 데이터베이서
- reshape
- tensorflow
- 머신러닝야학
- 데이터베이스 개론
- Today
- Total
IT's 우
생활코딩, 머신러닝(딥러닝)_세번째 딥러닝-아이리스 품종 분류 본문
아이리스 품종을 분류하는 딥러닝 모델을 텐서플로우를 이용하여 만들어 보고,
분류모델과 회귀모델의 차이점을 이해하자.
범수형 변수의 처리 방법인 원핫인코딩을 해야하는 이유와
활성화함수 softmax를 사용하는 이유를 학습하기.
소스코드, 결과
github csv url: https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv
# 라이브러리 사용
import tensorflow as tf
import pandas as pd
# 1.과거의 데이터를 준비합니다.
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv'
아이리스 = pd.read_csv(파일경로)
아이리스.head()
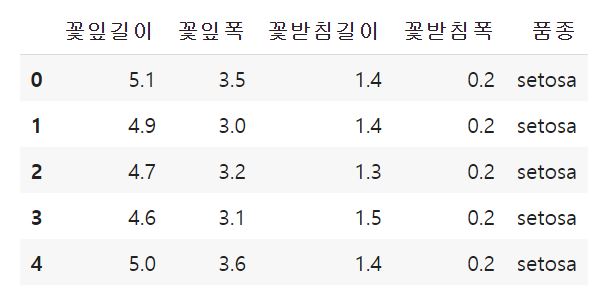
//종속변수의 데이터타입이 범주형이므로 분류(classification)모델임을 알 수 있다.
//종속변수의 데이터타입이 양적데이터라면 회귀(regression)모델을 사용한다.
# 원핫인코딩 *********************
인코딩 = pd.get_dummies(아이리스)
인코딩.head()
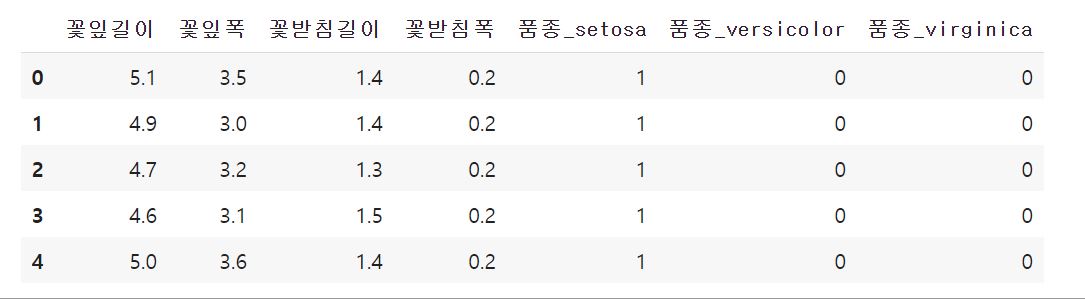
print(인코딩.columns)

# 독립변수, 종속변수
독립 = 인코딩[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
종속 = 인코딩[['품종_setosa', '품종_versicolor','품종_virginica']]
print(독립.shape, 종속.shape)
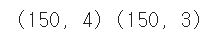
# 2. 모델의 구조를 만듭니다.
X = tf.keras.layers.Input(shape=[4])
Y = tf.keras.layers.Dense(3, activation='softmax')(X)
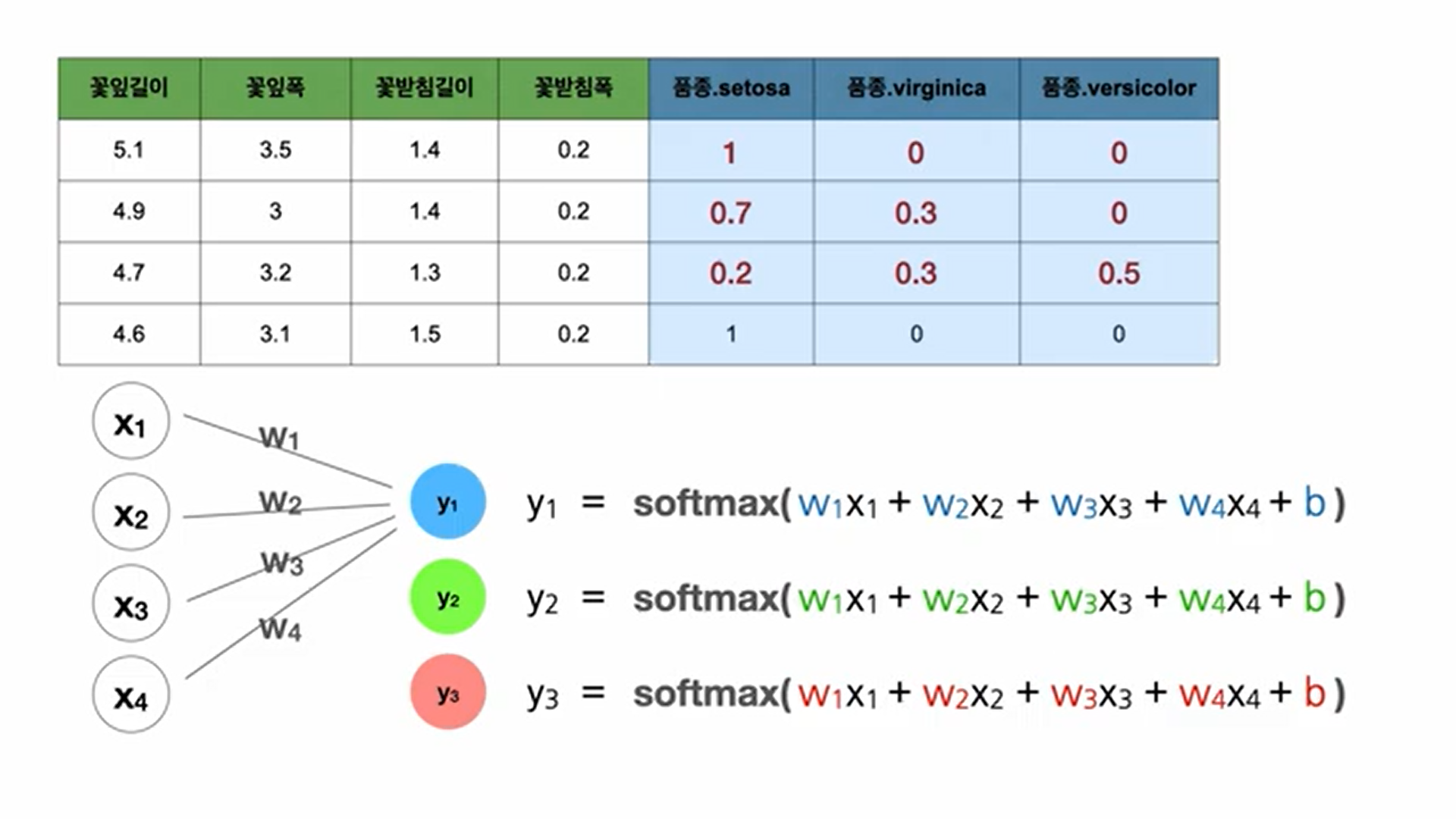
model = tf.keras.models.Model(X,Y)
model.compile(loss='categorical_crossentropy')
metrics=['accuracy'])

# 3. 데이터로 모델을 학습(FIT)합니다.
model.fit(독립, 종속, epochs=100)

loss값이 줄어드는 것을 확인할 수 있다.
# 모델을 이용합니다. 맨 마지막 데이터 5개
model.predict(독립[-5:])

print(종속[-5:])

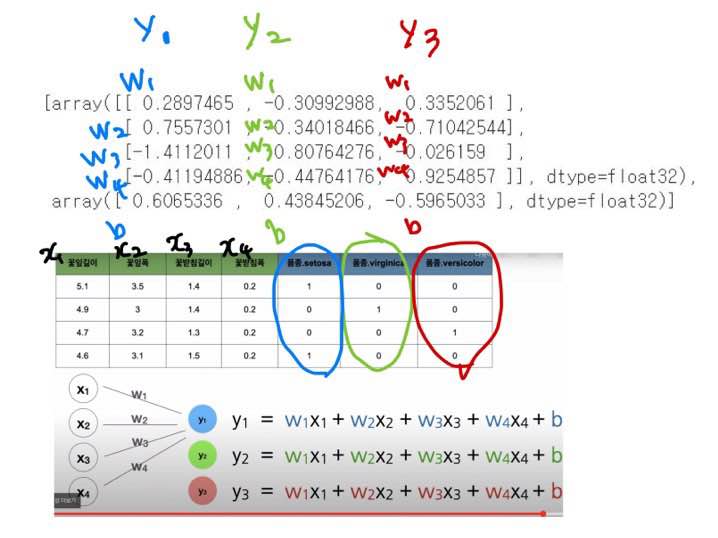
# 학습한 가중치
model.get_weights()

전체 소스코드
###########################
# 라이브러리 사용
import tensorflow as tf
import pandas as pd
###########################
# 1.과거의 데이터를 준비합니다.
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv'
아이리스 = pd.read_csv(파일경로)
아이리스.head()
# 원핫인코딩
아이리스 = pd.get_dummies(아이리스)
# 종속변수, 독립변수
독립 = 아이리스[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
종속 = 아이리스[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(독립.shape, 종속.shape)
###########################
# 2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[4])
Y = tf.keras.layers.Dense(3, activation='softmax')(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
###########################
# 3.데이터로 모델을 학습(FIT)합니다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)
###########################
# 4. 모델을 이용합니다
# 맨 처음 데이터 5개
print(model.predict(독립[:5]))
print(종속[:5])
# 맨 마지막 데이터 5개
print(model.predict(독립[-5:]))
print(종속[-5:])
###########################
# weights & bias 출력
print(model.get_weights())
출처: 생활코딩
'생활코딩 > 머신러닝(텐서플로우(python))' 카테고리의 다른 글
| 생활코딩, 머신러닝야학_데이터를 위한 팁(astype(), dtypes, isna().sum(), fillna()) (0) | 2021.01.15 |
|---|---|
| 생활코딩, 머신러닝(딥러닝)_네번째 딥러닝 - 신경망의 완성:히든레이어 (0) | 2021.01.14 |
| 생활코딩, 머신러닝(딥러닝)- 학습의 실제(with 워크북) (0) | 2021.01.14 |
| 생활코딩, 머신러닝(딥러닝)- 두번째 딥러닝 - 보스턴 집값 예측 (0) | 2021.01.14 |
| 생활코딩, 머신러닝(딥러닝)- 첫번째 딥러닝 - 레모네이드 판매 예측 (0) | 2021.01.13 |



